Obsah
Poslední změna: pondělí 9. března 2009
Napište program, který bude z několika souborů načítat čísla s pohyblivou řádovou čárkou (double) a bude je online[1] sčítat. Výsledkem tedy bude jeden součet všech čísel ve všech souborech. Nezapomeňte na to, že operace s desetinnými čísly nejsou atomické. Po spuštění se program zeptá na jméno souboru. Po zadání jména se začne sčítání provádět na pozadí a uživatel okamžitě uvidí výzvu na zadání dalšího souboru. Zadá-li uživatel ihned další jméno, bude se zpracovávání souborů provádět paralelně. Vždy po dokončení zpracovávání jednoho souboru bude vypsán aktuální stav celkového součtu.
Pomocí semaforu omezte maximální počet paralelně spuštěných výpočtů
na deset. Po zadání znaku konce souboru (Ctrl-D,
fgets() vrací NULL) program počká na dokončení všech
vláken a vypíše celkový součet. Pro čekání na ukončení vláken nemusíte
používat podmínkové proměnné, i když by se zde hodily.
Pro testování vašeho programu použijte soubor
/var/tests/a, který obsahuje čísla jejichž
součet je přesně 10 000 000. Pokud úlohu testujete mimo školu,
je možné testovací soubor stáhnout zde.
Prosím, nenechávejte jeho kopie ani jiné soubory zbytečně zabírající místo
v domácích adresářích. Hříšníci budou odhaleni a data jim budou smazána.
Pro načítání názvů souborů z klávesnice použijte kód podobný následujícímu:
fgets(name, 100, stdin); name[strlen(name)-1] = '\0'; # odstraní znak konce řádku \n
Pro převod řetězce na číslo typu double použijte funkci:
cislo = strtod(retezec_s_cislem, NULL);
Vlákny nazýváme paralelně prováděné funkce v rámci jednoho procesu. Vlákna jsou dost podobná procesům (jsou také prováděna paralelně), ale mezi procesy a vlákny je několik podstatných rozdílů. Každý proces se skládá jednak z kódu programu a jednak z dalších zdrojů jako například mapování virtuální paměti či tabulky otevřených souborů. Při přepínání procesů ve víceúlohovém systému je potřeba provést přemapování virtuální paměti, což je časově náročná operace. Protože je výhodné programovat paralelním stylem, tzn. rozdělit řešení nějakého problému na několik menších problémů, které jsou vyřešeny samostatně, ale prováděny současně, hledala se jiná alternativa k procesům, která by neměla takové režijní náklady. Tou náhradou jsou právě vlákna (threads). Při přepínání vláken z jednoho procesu se nemusí přemapovávat virtuální paměť. Vlákna sdílí téměř všechny prostředky procesu. Konkrétně se jedná o
instrukce programu,
většinu dat,
otevřené soubory (deskriptory)
signály a jejich obslužné rutiny (handlery).
Naproti tomu, každé vlákno má vlastní
identifikátor vlákna (Thread ID),
hodnoty registrů včetně ukazatele zásobníku,
zásobník,
chybovou proměnnou
errno.
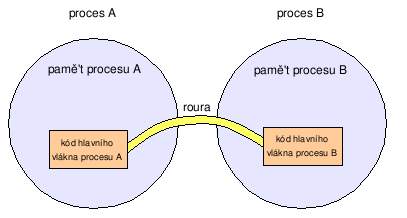
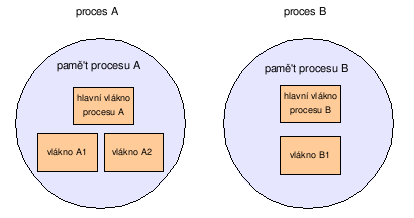
Rozdíly mezi procesy a vlákny mohou být patrny i z následujících obrázků. Různé procesy mezi sebou nesdílí paměť, kdežto vlákna v jednom procesu ji sdílí. Vlákna v jednom procesu tudíž nemusí (ale můžou) používat ke komunikaci mezi sebou prostředky meziprocesní komunikace.
Obrázek 1. Procesy – pro předávání dat mezi procesy je nutno použít meziprocesní komunikace (např. roury)
Základní funkce pro práci s vlákny jsou definovány v hlavičkovém
souboru pthread.h. Při používání vláken je výhodné
mít při překladu nadefinovaný symbol _REENTRANT,
který způsobí, že se budou automaticky používat reentrantní verze
některých funkcí z knihovny jazyka C.
Vytváření vláken –
int pthread_create(pthread_t * thread, pthread_attr_t * attr, void * (*start_routine)(void *), void * arg)Vytvoří nové vlákno. Do proměnné
threaduloží identifikátor vlákna. Pomocí proměnnéattrmůžeme specifikovat různé vlastnosti vytvářeného vlákna jako například počáteční prioritu. Pokud chceme použít implicitní atributy, stačí předat hodnotuNULL. Parametrstart_routineje ukazatel na funkci s kódem, který má vlákno provádět. Této funkci lze předat jeden parametrarg.Ukončení aktuálního vlákna –
void pthread_exit (void *RETVAL)Čekání na skončení vlákna –
int pthread_join(pthread_t th, void **thread_return)Pozastaví aktuální vlákno do doby, než skončí vlákno
th. Do proměnné, na kterou ukazuje ukazatelthread_returnbude uložen návratový kód vlákna.Pokud nás návratový kód vlákna nezajímá, je potřeba zavolat funkci
pthread_detach(pthread_t. Ta způsobí, že všechny zdroje, které vlákno používá budou uvolněny hned po skončení vlákna a ne až po zavoláníth)pthread_join().Násilné ukončení jiného vlákna –
int pthread_cancel(pthread_t thread)Identifikace aktuálního vlákna –
pthread_t pthread_self(void)
Vlákna jsou prováděna nezávisle na sobě. To je sice výhodné, ale v určitých situacích je potřeba zajistit aby tomu tak nebylo. Například, je potřeba zajistit, aby se několik vláken nesnažilo přistupovat ke stejným proměnným najednou. Častý je také případ, kdy jedno vlákno generuje nějaké data a druhé vlákno tato data zpracovává. Je jasné, že tato vlákna spolu musí nějak spolupracovat a právě k tomu slouží různá synchronizační primitiva.
Mutex je asi nejjednodušším prostředkem pro synchronizaci vláken.
Používá se pro zamykání globálních proměnných a struktur, ke kterým se
přistupuje z více vláken. Vlákno může mutex zamknout pomocí funkce
pthread_mutex_lock() a odemknout pomocí funkce
pthread_mutex_unlock(). Mutex může být zamnut
maximálně jedním vláknem a proto se často používá právě pro
synchronizaci přístup ke sdíleným proměnným.
Chybám, které vznikají špatným zamykáním proměnných se říká chyby souběhu (race conditions). Tyto chyby jsou velmi časté a jejich ladění je často problematické. Příklad programu, který obsahuje chyby souběhu je zde. Po přidání mutexů se program už chová správně.
Zatímco mutexy poskytují prostředky pro synchronizaci přístupu k proměnných, podmínkové proměnné umožňují synchronizovat vlákna na základě hodnot proměnných. Kdybychom neměli podmínkové proměnné, muselo by se v programu cyklicky testovat, zda už má proměnná žádanou hodnotu. Takový přístup by znamenal drastické snížení výkonu aplikace.
Více o podmínkových proměnných je např. zde.
Semafory jsou velmi podobné mutexům. Zatímco mutex má jen dva
stavy – zamknut/odemknut, semafor jich může mít víc. Semafor je v
podstatě čítač, který může být zmenšován a zvětšován. Když je čítač
roven nule je semafor považován za zamčený, v opačném případě je
odemčen. Semafory se používají, pokud máme omezený počet nějakých
zdrojů. Pokud nějaké vlákno chce ke zdroji přistupovat, zmenší hodnotu
semaforu (sem_wait). Pokud semafor nebyl roven
nule, proces pokračuje dál, v opačném případě čeká, až jiné vlákno
přestane zdroj používat a hodnotu semaforu zvětší
(sem_post).
Semafor se inicializuje funkcí sem_init(),
které předáme počáteční hodnotu čítače. Funkcí
sem_destroy() se semafor zruší.
[1] V okamžiku, kdy je načteno další číslo, je přičteno k celkovému součtu. Tedy ne, že se nejdříve sečtou čísla v jednom souboru a pak se výsledek přičte ke globálnímu součtu.
Všechny připomínky k předmětu, obsahu stránek, objevené chyby v ukázkových programech apod. adresujte na autory: